


出品|搜狐科技
作者|郑松毅
编辑|杨锦
AI大模型“角斗场”,被来自中国的“黑马”掀翻了天。
DeepSeek最新出品的R1模型,发布不到一周的时间,已经成功跃升至全球模型排行榜第三名,与OpenAI的GPT-4o并列。
截至北京时间1月26日17:50分,DeepSeek在美区苹果App Store免费榜升至第六位,超过谷歌Gemini、微软Copilot。或是由于短期内涌入用户太多,今日下午还有网友反映DeepSeek出现了短时闪崩现象。
值得一提的是,R1不仅是开源模型,训练成本要比GPT-4o足足便宜20倍。
DeepSeek也因此获得了不少新称号,诸如“国产AI之光”、“AI届的拼多多”等。
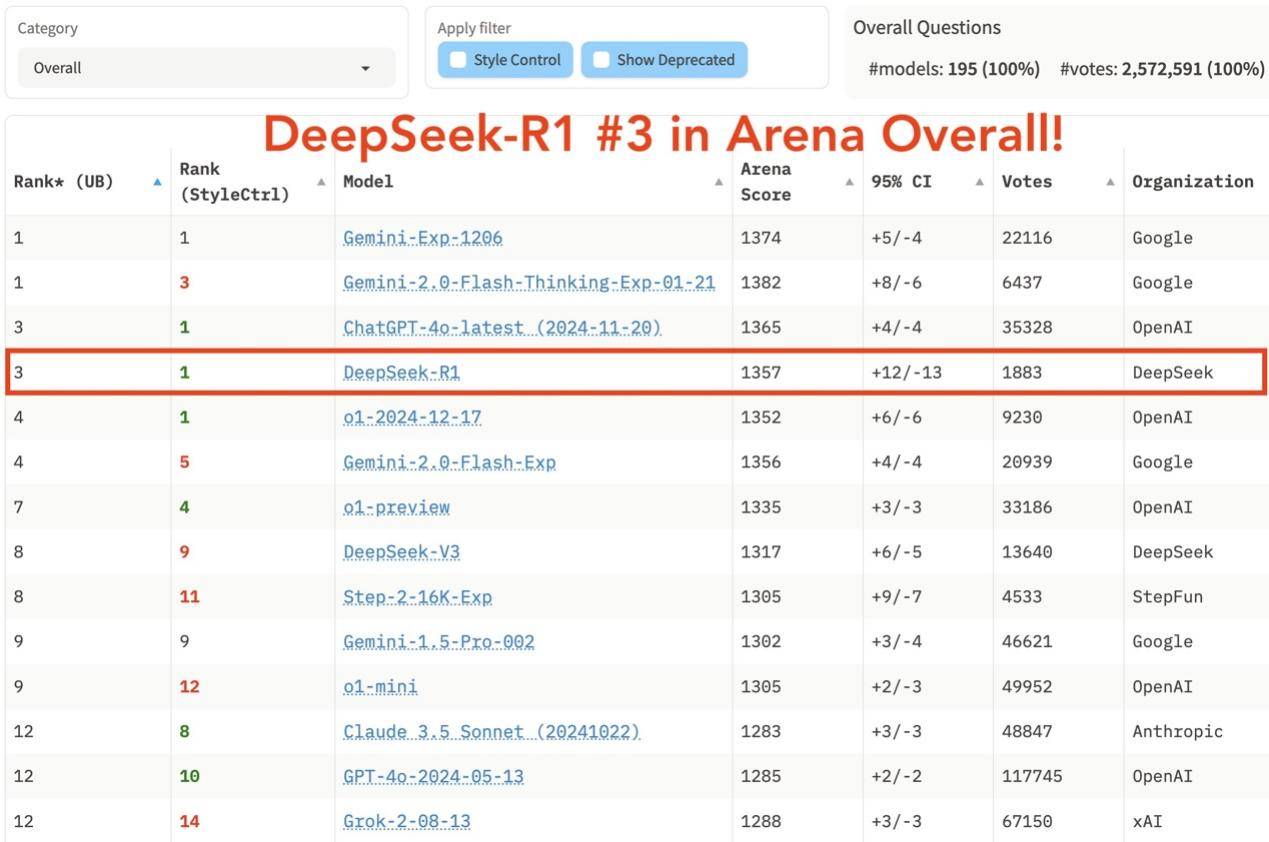
从DeepSeek公布的测试结果来看,在编码、数学、通识等方面,R1的表现都与OpenAI的o1模型旗鼓相当。

网友感叹,“是时候取消我昂贵的OpenAI模型订阅了。”也有在美网友刷屏评论,“美国的AI领先地位马上要不保了?”
图灵奖获得者杨立昆,从另一个角度发文表示,“比‘中国超越了美国’更合适的说法是,开源模型这次真正取得了胜利。”
硅谷好奇心不减
中国研发企业DeepSeek的“横空出世”,引起硅谷AI界的一众好奇。
无论是OpenAI、Meta、英伟达这样的科技巨头,还是杨立昆、吴恩达等顶尖AI学者,在对DeepSeek的评价中都出现了一个相同的形容词——“不可思议”。
据外媒报道,“Meta 的 AI 部门正感受到压力,工程师们正在疯狂地剖析 DeepSeek,并从中复制能复制的一切。”
DeepSeek“出圈”,到底做对了什么?
简单来说,DeepSeek成功用低成本,训练出了高质量的大模型。且最难得的是,其仍在保持追求AGI的初心。
《福布斯》提到,“它让世界认识到,中国并未退出这场竞赛(AI)。”
自DeepSeek掀起热议以来,对其技术论文的解析很多。概括来看,DeepSeek没有选择搭已有模型架构的“便车”,而是选择了创新。
复旦大学教授、MOSS大模型项目负责人邱锡鹏向搜狐科技介绍,“DeepSeek这次主要是AI Infra(AI基础设施,包括AI部署、算力管理等)做得好,高效利用了资源。”
在R1模型的训练过程中,DeepSeek直接将强化学习(RL)应用于基础模型,而非像以往依靠人类标注数据进行监督微调(SFT)。这样做的目的是,让模型从零开始“自我进化”,从而获得推理能力。
有个比喻很得当,“就像人学习语文,是从偏旁部首和拼音基础知识学起,而不是在任何人的指导下直接学习造句。这样打下的基础更扎实。”
此外,虽然DeepSeek和OpenAI都选用了Transformer架构,但DeepSeek采用了全新的“多头潜在注意力机制架构(MLA)”,大幅减少了计算量,提升模型训练效率。
综合以上,DeepSeek收获的结果就是——绝对的性价比。便宜到什么程度?看其公布的一张价格对比图便知。
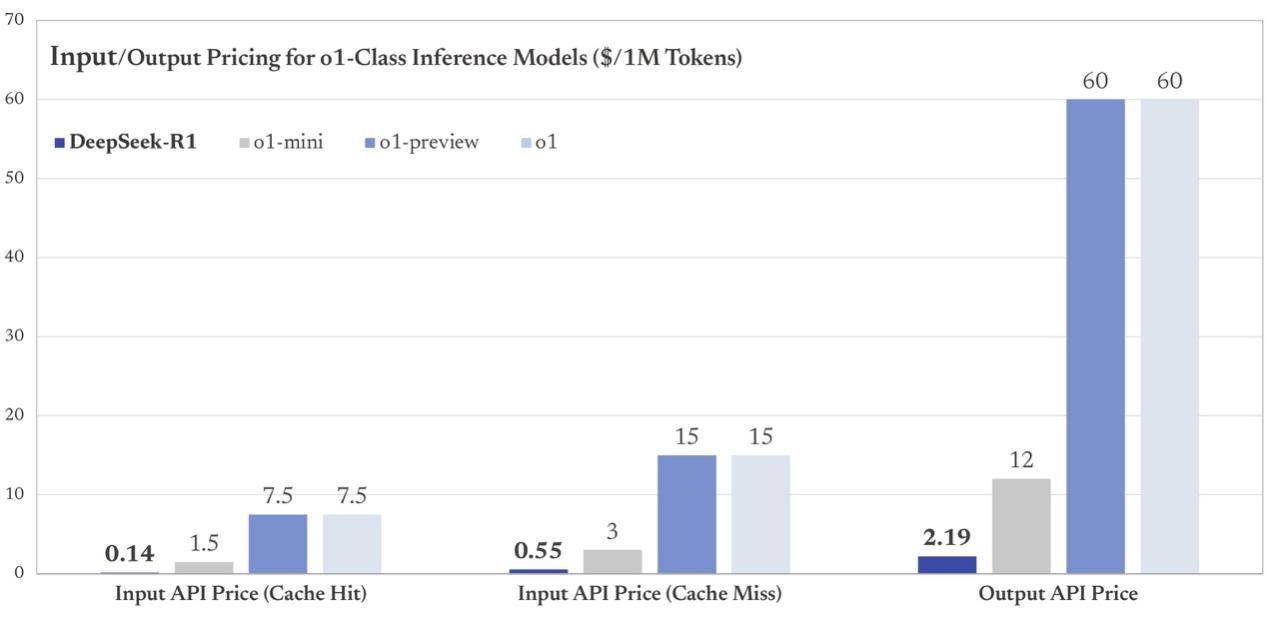
无论是输入还是输出Token价格,DeepSeek都要比OpenAI的o1模型便宜数十倍,且性能表现与其相当。
鲜为人知的是,在去年引燃的“大模型价格战”,也正是由DeepSeek掀起的。
在DeepSeek宣布降价后,字节、阿里巴巴、百度等一众国内大厂跟进,甚至不惜“烧钱补贴”。
在与暗涌的一场对话中,DeepSeek创始人梁文锋对不断降价的“打法”解释道,“抢用户并不是我们的主要目的。降价一方面是因为我们在探索下一代模型的结构中,成本先降下来了,另一方面也觉得无论 API,还是 AI,都应该是普惠的、人人可以用得起的东西。”
一群“疯狂”的人
DeepSeek既不在中国大模型“六小虎”之列,也不像百度、阿里巴巴等科技大厂,在AI竞赛一开始就备受瞩目。
DeepSeek真正在AI圈内闯出名声,是在2024年5月发布高性价比模型DeepSeek V2,在激烈竞争中为自己占得了“一席之地”。
与很多外界的猜测不同,DeepSeek没有高深莫测的“奇才”,都是一些Top高校的毕业生,或是博四、博五没毕业的实习生。
如今,DeepSeek正在掀起新的一场“复刻狂潮”,只有强化学习,没有监督微调。
Meta、UC伯克利、香港科技大学等一众产学界机构,正在用“放大镜”深研DeepSeek论文,并尝试复现。或许,全世界正在进入AI的下一分水岭。
谈及对突然“出圈”的看法,梁文锋给出的解释是,“在美国每天发生的大量创新里,这是非常普通的一个。之所以惊讶,是因为这次中国是以创新者的身份出现,而不是刻板印象中的follow(跟随者)。”
对于未来,梁文锋和团队想的很清楚,“要参与到全球创新浪潮中去,而不是习惯于拿别人的创新过来,做应用变现。”
在他看来,“中国并不缺人才,DeepSeek的V2模型没有海外的人参与,都是本土的。前 50 名顶尖人才可能不在中国,但也许我们能自己打造这样的人。”
前面提到, DeepSeek最难得的是仍在坚持追求AGI的纯粹技术初心。
北京智源人工智能研究院副院长兼总工程师林咏华曾向搜狐科技介绍,“放眼当下AI市场,大家对应用的追求是强烈的,反观仍在追求AGI的研究团队数量却在不断减少,高昂的科研成本劝退了很多人。”
DeepSeek的身上,背负着同样的压力。在梁文锋的表述中,能够清晰感受到创新就是昂贵且低效的。投资人也会出于商业利益的考量对项目信心时而不定。
但这一切,似乎并未影响梁文锋和他的年轻团队成为一群“疯狂”的人,在泥泞的道路上,坚持追寻挂在天边的“技术理想”。
中美AI差距不存在了吗?
DeepSeek的成绩可观,是否意味着中国AI发展已经赶超了美国?
360集团创始人周鸿祎在最新发布的视频中表示,“中美现在AI竞争日益激烈,但最终一定是中国胜利。就像中国在制造业领域已经战胜了美国一样,中国AI公司的创造力已经刹不住车了。”
“将来如果要对抗美国的AI技术霸权,中国大模型技术复仇者联盟战队里一定有DeepSeek的一份,因为这家公司和它的创始人非常低调,他们技术能力和未来前景被市场严重低估了。”周鸿祎说。
清华大学计算机系长聘副教授刘知远认为,“中国和美国的AI差距明显缩小了,很多人不信服,现在DeepSeek等用实例让大家看到了这点。”
但他强调,“最近看到越来越多‘中国AI已经超过美国’、‘DeepSeek羞辱OpenAI’的说法,我觉得不太好。要警惕从极度悲观转向了极度乐观。觉得我们已经全面超越、遥遥领先了,远远没有。”
他提到,“AGI新技术还在加速演进,未来发展路径尚不明确。我们仍在追赶阶段,已经不是望尘莫及,但也只能说是望其项背。”
“在别人已经探索出来的路上跟随快跑是相对容易的,接下来我们要面对一团未来迷雾,如何先人一步探出新路,是更困难和有挑战的事,需要百倍投入、百倍努力。”
在刘知远看来,DeepSeek出圈的意义是,“非常好的让人们看到中国AI的希望,但远未到胜券在握、优势在我的地步。我们在人才储备、算力资源和创新生态方面还有巨大差距。只有头脑清醒、发挥自身优势,不断弥补差距,才能走好后面更有挑战的路。”
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






